오늘은 온보딩 강의 마지막 날이다
2주동안 3시간씩 진행하는 수업이었는데 벌써 끝이라니...
그러면 바로 학습한 것들 정리 시작하겠다!
쿠버네티스란?
컨테이너화된 애플리케이션의 자동 배포, 확장, 운영을 위한 오픈소스 플랫폼
서버의 한계에서부터 생각해보자...🤔
통상적으로 물리적인 서버 한 대에 도커가 설치 되어있고, 이를 통해 여러 애플리케이션을 운영하고 있다.
초기에는 이 구성만으로도 충분할 수 있지만, 사용자 수가 증가하면 서버의 리소스가 부족해지기 시작할 거고,이에 대응해야 하는 때가 분명히 올 것이다.
그러면 우리는 어떻게 대응을 해야 할까?
이러한 상황에서 우리는 크게 두 가지 방법, 스케일 업(Scale Up)과 스케일 아웃(Scale Out)을 고려할 수 있다.
뒤에서 자세히 설명하겠지만 간단하게 설명하자면 스케일 업은 기존 서버의 성능을 강화하는 것을 의미하며,스케일 아웃은 더 많은 서버를 추가하여 처리 능력을 확장하는 방법이다.
하지만 이러한 작업을 수동으로 진행하기에는 매우 복잡하고 시간이 많이 소요된다.
여기서 쿠버네티스의 역할이 중요해지는데, 쿠버네티스를 사용하면, 애플리케이션을 컨테이너 단위로 쉽게 배포하고, 사용량에 따라 자동으로 스케일 업 또는 스케일 아웃을 할 수 있다. 즉, 개발자와 시스템 관리자는 인프라의 복잡성을 신경 쓰지 않아도 되고, 애플리케이션의 개발과 배포에 더 집중할 수 있게 된다.
쿠버네티스의 장점
- 성능 유지
- 서버는 동시에 처리할 수 있는 요청의 수에 한계가 있다. 사용자 수가 증가하면, 동시 요청의 수가 늘어나고 이는 서버의 처리 능력을 초과할 수 있다. 서버를 늘려서 이러한 요청을 효화적으로 분산시키면, 시스템의 응답 시간을 개선하고 사용자 경험을 유지할 수 있다.
- 가용성 향상
- 단일 서버에 문제가 발생하면 전체 서비스에 영향을 미칠 수 있다. 서버를 여러 대 운영하면 하나의 서버에 문제가 생겨도 다른 서버가 처리를 계속 수행할 수 있어 서비스의 중단 시간을 줄일 수 있다. 이는 고가용성을 보장하는 데 중요하다.
💡 서버에서 "가용성"이란?
서버 또는 네트워크 시스템이 계획된 운영 시간 동안 얼마나 안정적으로 접근 가능하고, 정상적으로 가능하는지를 나타내는 지표이다. 기본적으로, 가용성은 시스템이 사용자의 요구를 충족시키며 요청된 서비스를 제공할 수 있는 능력을 의미. (=업타임)
가용성을 높이는 방법
- 하드웨어 중복: 중요한 서버 및 네트워크 구성요소를 복제하여 하나가 실패해도 다른 하나가 기능을 지속할 수 있게 한다.
- 로드 밸런싱: 여러 서버에 걸쳐 트래픽을 분산시키는 방법으로, 하나의 서버에 문제가 발생하더라도 전체 시스템이 계속 작동하도록 한다.
- 장애 조치(failover) 시스템: 주 서버가 실패할 경우 자동으로 백업 시스템으로 전환하여 운영을 지속할 수 있게 하는 시스템이다.
- 정기적인 백업 및 복구 테스트: 데이터를 정기적으로 백업하고, 장애 발생 시 복구 프로세스가 효과적으로 작동하는지 주기적으로 테스트한다.
- 분산 아키텍처: 지리적으로 분산된 데이터 센터를 사용하여 자연 재해나 지역적 장애의 영향을 최소화한다.
가용성을 측정하는 방법
- 모니터링 도구 사용
- 실시간 모니터링: 애플리케이션과 인프라의 실시간 모니터링을 통해 성능 지표를 지속적으로 추적할 수 있다.
Datadog, New Relic, Prometheus 같은 도구들은 시스템의 중요한 메트릭을 수집하고, 문제가 발생할 때 알림을 제공한다. - Uptime 모니터링 서비스: Uptime Robot, Pingdom 등의 서비스를 사용하여 애플리케이션의 가용성을 주기적으로 체크하고, 다운타임이 발생했을 때 즉시 알림을 받을 수 있다.
- 실시간 모니터링: 애플리케이션과 인프라의 실시간 모니터링을 통해 성능 지표를 지속적으로 추적할 수 있다.
- 부하 테스트
- 부하 테스트 도구 사용: Apache JMeter, Gatling, LoadRunner와 같은 도구를 사용하여 애플리케이션에 고객 예상 트래픽 이상의 트래픽을 생성하고, 애플리케이션의 성능을 측정한다. 이를 통해 트래픽 증가 시 애플리케이션의 반응을 확인하고 최적화할 수 있다.
- 장애 조치(Failover) 테스트
- 재난 복구 시나리오 실행: 정기적으로 장애 조치 테스트를 실행하여, 주요 시스템 구성요소가 실패했을 때의 대응을 평가한다. 예를 들어, 데이터베이스 서버가 다운되는 경우, 자동 장애 조치가 얼마나 잘 작동하는지를 확인할 수 있다.
- 카오스 엔지니어링
- 카오스 몽키 도구 활용: Netflix의 Chaos Monkey와 같은 도구를 사용하여 의도적으로 인프라 내에 장애를 일으켜 보고 시스템이 이를 어떻게 처리하는 지 관찰한다. 이는 시스템의 복원력을 강화하고 잠재적인 취약점을 발견하는 데 유용하다.
- 벤치마킹
- 성능 벤치마킹: 다른 유사 애플리케이션 또는 이전 버전의 애플리케이션과의 성능을 비교 분석한다. 이를 통해 현재 애플리케이션의 성능 지표가 업계 표준이나 기대치를 충족하는지 평가할 수 있다.
- 이러한 방법을 통해 애플리케이션의 가용성을 정기적으로 검토하고 평가함으로써, 시스템의 안정성을 유지하고 사용자 만족도를 높일수 있다. 이는 또한 미래의 확장성 및 유지관리 계획에 중요한 데이터를 제공한다.
가용성을 향상시키는 방법
- 부하 분산 (Load Balancing): 부하 분산기를 사용하여 여러 서버에 요청을 균등하게 분배함으로써 각 서버의 부하를 줄일 수 있다.
- 스케일링: 사용자의 요구와 트래픽에 따라 서버의 리소스를 증가시키거나 감소시키는 스케일 아웃 또는 스케일 업을 실행한다.
- 캐싱: 자주 요청되는 데이터를 캐시에 저장하여, 동일한 요청에 대해 서버가 반복적으로 같은 계산을 수행하는 것을 방지할 수 있다.
그 중 현대에는 스케일 아웃 전략을 많이 사용한다.
스케일 아웃(Scale Out)란?
시스템의 처리 능력을 증가시키기 위해 추가적인 하드웨어 유닛이나 노드를 서버 클러스터에 추가하는 것을 의미
스케일 아웃을 선호하는 이유
- 유연성과 확장성: 스케일 아웃은 서버나 리소스를 필요에 따라 추가하거나 제거할 수 있어 매우 유연함. 사용자 수나 처리해야 할 데이터가 증가함에 따라 서버를 추가적으로 배치하여 쉽게 확장할 수 있다. 이는 빠르게 변화하는 비즈니스 요구사항과 트래픽 패턴에 효과적으로 대응할 수 있게 해준다.
- 비용 효율성: 수평 확장은 일반적으로 추가적인 고성능 서버를 구매하는 것보다 비용이 효율적이다. 저렴한 표준 하드웨어나 클라우드 리소스를 사용하여 시스템을 확장할 수 있기 때문에 초기 투자 비용과 운영 비용을 낮출 수 있다.
- 고가용성: 스케일 아웃 아키텍처는 자연스럽게 고가용성을 제공한다. 여러 노드에서 애플리케이션을 운영함으로써 하나의 노드가 실패하더라도 시스템 전체의 가동 중단 없이 다른 노드가 작업을 계속 수행할 수 있다. 이는 비즈니스 연속성을 보장하며, 장애 복구 시간을 최소화한다.
- 부하 분산: 수평 확장을 통해 트래픽이나 작업 부하를 여러 서버에 분산시킬 수 있다. 이는 단일 서버에 과부하가 걸리는 것을 방지하고, 시스템의 전체적인 처리 성능을 향상시킬 수 있다.
- 기술 발전과 클라우드 컴퓨팅: 클라우드 컴퓨팅 기술의 발전은 스케일 아웃을 쉽고 접근하기 쉬운 옵션으로 만든다. 클라우드 서비스 제공자들은 사용자가 손쉽게 리소스를 추가하거나 줄일 수 있는 유연한 서비스를 제공한다. 또한, 클라우드 기반의 스케일 아웃은 물리적 인프라에 대한 우려 없이 글로벌 사용자 기반을 효과적으로 서비스할 수 있게 해준다.
스케일 아웃을 통해 서버의 수가 늘어나고 도커 컨테이너의 수 증가 -> 이러한 컨테이너들을 효과적으로 관리하고 조정하는 것이 매우 중요해짐 -> 도커 오케스트레이션 기술의 대두
도커 오케스트레이션의 중요성
- 자동화된 관리: 도커 오케스트레이션 도구는 컨테이너의 배포, 관리 및 확장을 자동화하여, 수동 작업의 필요성을 크게 줄여준다. 이는 시간과 리소스를 절약할 수 있게 해준다.
- 확장성: 오케스트레이션 도구를 사용하면 컨테이너를 쉽게 스케일 아웃할 수 있다. 예를 들어, 트래픽이 증가할 때 자동으로 컨테이너의 수를 늘릴 수 있으며, 필요하지 않을 때는 줄일 수 있다.
- 부하 분산: 여러 컨테이너와 서버에 걸쳐 트래픽과 부하를 자동으로 분산시키는 기능을 제공한다. 이는 서비스의 가용성과 성능을 향상시킨다.
- 서비스 발견과 네트워킹: 오케스트레이션 도구는 컨테이너 간의 네트워킹과 서비스 발견을 관리한다. 각 컨테이너가 필요한 리소스와 서비스를 찾아서 소통할 수 있도록 지원한다.
- 상태 관리와 자가 치유: 시스템이 정의한 상태를 유지하도록 설정할 수 있으며, 문제가 발생했을 때 오케스트레이션 도구가 자동으로 문제를 해결하려고 시도한다. 예를 들어, 실패한 컨테이너를 자동으로 재시작할 수 있다.
도커 오케스트레이션 도구
- Kubernetes: 현재 가장 널리 사용되는 컨테이너 오케스트레이션 플랫폼으로, 다양한 커뮤니티 지원과 기능을 제공
- Docker Swarm: Docker에서 공식적으로 지원하는 오케스트레이션 도구로, Docker 엔진에 내장되어 있어 설정이 간편하다
- Apache Mesos: 대규모 클러스터 관리에 적합하며, 데이터 센터를 하나의 리소스 풀처럼 다루어 높은 확장성과 장애 허용성을 제공
쿠버네티스의 구조

여러 컴포넌트와 리소스로 구성되어 있으며, 애플리케이션의 배포, 관리, 확장을 자동화함.
- 마스터 노드 (Master Node)
- 마스터 노드는 쿠버네티스의 클러스터의 제어 허브로서, 클러스터의 관리 및 조정을 담당한다. 여기에는 여러 핵심 컴포넌트가 포함된다.
- API 서버 (kube-apiserver): 클러스터와의 모든 통신을 처리하는 엔드포인트. 사용자, 외부 시스템, 클러스터 내부 컴포넌트들이 API 서버를 통해 상호작용한다.
- 컨트롤러 매니저 (kube-controller-manager): 다양한 컨트롤러를 실행. 이 컨트롤러들은 복제 컨트롤러, 엔드포인트 컨트롤러, 네임스페이스 컨트롤러 등이 있으며, 클러스터의 상태를 원하는 상태로 유지하는 데 필요하다.
- 스케줄러 (kube-scheduler): 새로 생성된 파드를 적절한 노드에 배치하는 역할. 파드의 요구 사항과 노드의 리소스 상태를 고려하여 배치 결정을 내린다.
- etcd: 모든 클러스터 데이터를 저장하는 경량 데이터베이스 시스템. 쿠버네티스의 모든 상태와 메타데이터를 저장하고, 클러스터의 신뢰할 수 있는 싱글 소스 오브 트루스로 작동한다.
- 마스터 노드는 쿠버네티스의 클러스터의 제어 허브로서, 클러스터의 관리 및 조정을 담당한다. 여기에는 여러 핵심 컴포넌트가 포함된다.
- 워커 노드 (Worker Nodes)
- 워커 노드들은 실제로 애플리케이션 컨테이너가 실행되는 서버임. 각 워커 노드는 다음과 같은 컴포넌트를 포함한다.
- kubelet: 각 노드에서 실행되는 에이전트로, 마스터 노드의 지시를 받아 컨테이너가 파드 내에서 올바르게 실행되도록 관리한다.
- kube-proxy: 네트워크 프록시 및 로드 밸런서 역할을 하는 컴포넌트로, 노드의 네트워크 규칙을 관리하고, 연결 및 트래픽 라우팅을 처리한다.
- 컨테이너 런타임: 컨테이너를 실행하기 위한 환경을 제공. Docker, containerd, CRI-O 등이 사용될 수 있다.
- 워커 노드들은 실제로 애플리케이션 컨테이너가 실행되는 서버임. 각 워커 노드는 다음과 같은 컴포넌트를 포함한다.
- 추가적인 구성요소
- 네트워크: 쿠버네티스는 파드 간의 통신을 위해 자체 네트워킹 모델을 제공. 각 파드는 고유한 IP 주소를 가지며, 파드 간에는 플랫 네트워크에서 서로 통신할 수 있다.
- 스토리지: 쿠버네티스는 볼륨을 사용하여 데이터를 저장. 로컬 스토리지, 네트워크 스토리지 (NFS, iSCSI 등), 클라우드 제공자의 스토리지 서비스 (예: AWS EBS, Azure Disk)등 다양한 스토리지 옵션을 지원한다.
쿠버네티스에서 노드(Node)는 파드(Pod)를 실행하는 물리적 또는 가상의 서버다. 파드는 쿠버네티스에서 기본적인 배포 단위로, 하나 이상의 컨테이너로 구성될 수 있다. 파드 내의 컨테이너들은 공유된 리소스와 정보를 가지며, 네트워크와 스토리지 같은 일부 측면에서 밀접하게 연관되어 함께 작동한다. 이러한 구조는 파드가 독립적으로 배포하고 관리될 수 있도록 함과 동시에, 효율적으로 리소스를 공유할 수 있게 해준다.
파드의 구성 요소와 특징
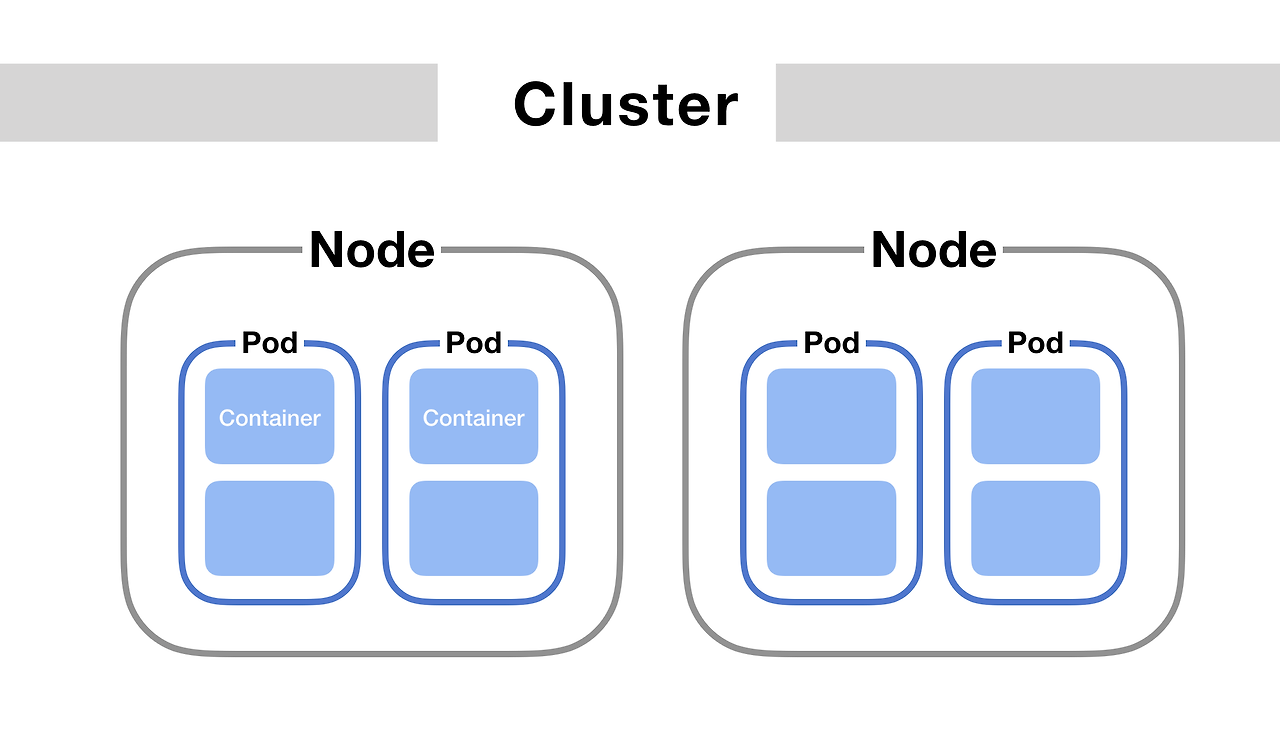
- 컨테이너
- 파드는 하나 이상의 컨테이너를 포함할 수 있다. 이 컨테이너들은 동일한 네트워크 및 UTS(Unix Time Sharing) 네임스페이스를 공유하며, 필요한 경우 IPC(Inter-process Communication)를 통해 통신할 수 있다.
- 일반적으로, 각 파드는 하나의 주요 애플리케이션 컨테이너를 포함하고, 추가적으로 사이드카 컨테이너를 포함할 수 있다. 사이드카 컨테이너는 로깅, 모니터링, 네트워크 프록시 등의 보조 기능을 제공한다.
- 공유 네트워크
- 파드는 하나 이상의 볼륨을 정의할 수 있다. 이 볼륨은 파드 내의 컨테이너들 사이에 공유되어 파일 시스템을 통한 데이터 공유를 용이하게 한다.
- 쿠버네티스는 다양한 유형읜 볼륨을 지원하며, 이는 파드가 스토리지에 종속되지 않고, 어떤 노드에서든 동일하게 작동할 수 있도록 한다.
- 생명주기와 관리
- 파드는 불변성을 가지며, 한 번 생성되면 그 내부의 컨테이너는 변경할 수 없다. 컨테이너를 업데이트 해야 할 경우, 파드를 새로 생성하고 교체하는 방식으로 처리한다.
- 파드는 일반적으로 복제(replication)를 통해 고가용성을 보장받는다. 쿠버네티스는 파드의 상태를 모니터링하고, 실패한 파드를 자동으로 대체하는 복제 컨트롤러나 레플리카셋을 사용하여 관리한다.
- 노드 내에서 각 파드는 독립적인 실행 환경을 제공받으며, 노드의 리소스(CPU, 메모리)를 할당받아 사용한다. 쿠버네티스 스케줄러는 파드를 적절한 노드에 스케줄링하여, 리소스 사용을 최적화하고 시스템의 전반적인 효율성을 높인다. 이러한 구조 덕분엔 쿠버네티스는 대규모, 분산된 컨테이너화된 애플리케이션의 관리를 간소화하고 자동화할 수 있다.

쿠버네티스 특징
- Self-healing
- "쿠버네티스는 실패한 컨테이너를 다시 시작하고, 컨테이너를 교체하며, '사용자 정의 상태 검사'에 응답하지 않는 컨테이너를 죽이고, 서비스 준비가 끝날 때까지 그러한 과정을 클라이언트에 보여주지 않는다."
- auto scaling
- 쿠버네티스의 오토스케일링(auto-scaling)은 시스템이 자동으로 파드의 수를 조정하여, 변화하는 워크로드에 따라 애플리케이션의 리소스 요구를 충족시킬 수 있도록 해주는 기능이다. 이는 특히 클라우드 환경에서 유용하며, 애플리케이션의 퍼포먼스를 유지하고 비용 효율성을 높이는 데 도움을 준다.
- 쿠버네티스는 두 가지 유형의 오토스케일링을 지원한다.
- Horizontal Pod Autoscaler (HPA)
- HPA는 CPU 사용량 또는 다른 선택된 메트릭을 기반으로 파드의 인스턴스 수를 자동으로 스케일 아웃(증가)하거나 스케일 인(감소)한다.
- 예를 들어, 특정 파드가 CPU 사용량이 80%를 초과할 때 추가 파드를 생성하고, 사용량이 50% 미만일 때 파드 수를 줄일 수 있다.
- HPA는 런타임에 리소스 사용률을 모니터링하고, 설정된 임계값에 따라 파드 수를 자동으로 조정한다.
- Cluster Autoscaler
- 쿠버네티스의 클러스터 오토스케일러(Cluster Autoscaler)는 클러스터 내에서 노드(서버)의 수를 동적으로 조정하여 파드의 수요에 따라 클러스터의 리소스를 최적화하는 역할을 한다. 여기에는 클러스터의 크기를 자동으로 확장하거나 축소하는 과정이 포함된다. 이러한 기능은 특히 클라우드 환경에서 유용하며, 사용량이 변동하는 애플리케이션에 이상적이다.
- 예를 들어, 모든 노드가 포화 상태이고 새로운 파드를 수용할 수 없는 경우, 클러스터 오토스케일러는 새로운 노드를 추가할 수 있다. 반대로 많은 노드가 사용되지 않고 리소스가 남아돌 때는 노드 수를 줄인다.
- Horizontal Pod Autoscaler (HPA)
- 예시: 온라인 쇼핑몰의 플래시 세일
- 상황: 온라인 쇼핑몰에서 큰 할인 행사를 진행하고 있다. 이 행사는 일반적인 날보다 많은 트래픽을 유발하며, 행사 시작 직전과 진행 중에 트래픽이 급격히 증가한다.
- 문제: 이러한 급격한 트래픽 증가는 기존에 구성된 서버 노드들로는 충분히 처리할 수 없다. 새로운 사용자 요청을 수용하기 위해 추가 리소스가 필요하다.
- 클러스터 오토스케일러의 역할
- 트래픽 감지: 클러스터 오토스케일러는 쿠버네티스 클러스터의 리소스 사용률을 지속적으로 모니터링한다. 파드가 필요로 하는 리소스와 현재 클러스터의 리소스 용량을 비교한다.
- 노드 추가: 행사 시작 직전에 트래픽이 증가하면, 클러스터 오토스케일러는 자동으로 더 많은 노드를 클라우드 인프라에서 프로비저닝한다. 이로써 새로운 사용자 요청을 수용할 수 있는 충분한 컴퓨팅 리소스를 확보할 수 있다.
- 부하 분산: 새롭게 추가된 노드는 기존 노드와 함께 트래픽을 분산 처리한다. 이는 시스템의 전반적인 부하를 줄이고 사용자 요청에 대한 응답 시간을 최적화한다.
- 노드 제거: 행사가 끝나고 트래픽이 정상으로 돌아오면, 클러스터 오토스케일러는 불필요해진 추가 노드를 자동으로 제거한다. 이는 비용 절감과 리소스 효율성 증대에 기여한다.
이러한 오토스케일링 기능은 쿠버네티스가 다양한 워크로드와 변동성이 큰 트래픽 조건에서도 애플리케이션을 안정적으로 운영할 수 있도록 지원하고, 리소스 사용을 최적화하여 운영 비용을 관리하는 데 큰 이점을 제공한다.
쿠버네티스의 Automated rollouts와 rollbacks 기능
애플리케이션의 배포 과정을 자동화하여, 새로운 버전의 애플리케이션을 안전하게 배포하고 필요한 경우 이전 버전으로 롤백할 수 있게 하는 기능이다. 이러한 기능은 배포의 안정성을 향상시키고, 운영 팀의 수작업 부담을 줄여준다.
- Automated Rollouts (자동 배포)
- 쿠버네티스에서 애플리케이션 또는 서비스의 새로운 버전을 배포할 때, 롤아웃은 새로운 버전을 점진적으로 적용하는 과정이다. 이 과정에서 쿠버네티스는 새로운 파드를 순차적으로 생성하고, 문제가 없는 것을 확인하면서 점진적으로 트래픽을 새 버전으로 이동시킨다.
- 롤아웃 도중에 파드의 상태를 지속적으로 모니터링하여, 예상치 못한 문제나 에러 발생 시 롤아웃을 자동으로 일시 중지한다. 이를 통해 잠재적인 장애가 전체 시스템에 영향을 미치기 전에 조치를 취할 수 있다.
- Automated Rollbacks (자동 롤백)
- 롤백은 새로운 버전의 배포가 실패하거나 문제를 일으킬 경우, 자동으로 이전 버전으로 돌아가는 과정이다. 롤백은 배포된 리소스의 이전 구성 상태로 되돌리는 것을 의미한다.
- 롤백을 통해 새로운 버전에서 발견된 문제로 인한 서비스 중단이나 장애를 최소화할 수 있다. 쿠버네티스는 배포 이력을 추적하고, 각 배포 버전의 상태를 관리함으로써 언제든지 안전하게 이전 상태로 되돌릴 수 있도록 지원한다.
CI/CD를 사용하는 클라우드 서비스
- AWS (Amazon Web Services)
- AWS CodePipeline: 소스 코드에서 배포까지 전체 프로세스를 자동화하고 관리하고 있다.
- AWS CodeBuild: 소스 코드를 컴파일하고, 테스트를 실행하며, 소프트웨어 패키지를 생성하는 빌드 서비스
- AWS CodeDeploy: 자동화된 소프트웨어를 AWS 인스턴스에 배포
- Microsoft Azure
- Azure Pipelines: 지속적 통합과 배포를 지원하고 있으며, GitHub 및 다른 버전 관리 시스템과 통합되고 있다
- Azure DevOps Services: 개발 팀이 코드를 공유하고, 작업을 추적하며, 소프트웨어를 배포하기 위한 종합적인 서비스를 제공하고 있다
- Google Cloud Platform (GCP)
- Google Cloud Build: 코드를 컴파일하고, 테스트를 실행하며, 컨테이너를 빌드하기 위한 서비스이다
- Cloud Deployment Manager: 자동화된 배포와 리소스 관리를 제공하고 있다
- GitLab
- GitLab CI/CD: GitLab은 자체적으로 강력한 CI/CD 도구를 제공하고 있으며, 코드 저장소에서 바로 파이프라인을 구성하고 실행할 수 있다
Docker를 사용하는 클라우드 서비스
- Amazone Web Services (AWS)
- Amazon Elastic Container Service (ECS): AWS에서 도커 컨테이너를 쉽게 실행, 중지 및 관리할 수 있게 해주는 컨테이너 관리 서비스이다
- AWS Fargate: 서버를 관리할 필요 없이 컨테잉너를 직접 실행할 수 있는 서버리스 컴퓨트 엔진이다
- Amazon Elastic Kubernetes Service (EKS): 쿠버네티스 기반의 관리 서비스로, 도커 컨테이너를 쿠버네티스 클러스터에서 쉽게 실행할 수 있다
- Microsoft Azure
- Azure Container Instances (ACI): 서버를 관리할 필요 없이 도커 컨테이너를 Azure에서 빠르게 시작하고 실행할 수 있다
- Azure Kubernetes Service (AKS): 쿠버네티스 기반의 관리 서비스로, 도커 컨테이너를 확장성 있게 관리할 수 잇다.
- Google Cloud Platform (GCP)
- Google Kubernetes Engine (GKE): 도커 컨테이너를 쿠버네티스 클러스터에서 관리하고 확장하는 데 사용되는 서비스이다
- Google Cloud Run: 도커 컨테이너를 서버리스 환경에서 실행할 수 있으며, 사용한 만큼만 비용을 지불하게 된다
실습 - github action 사용해서 ecr에 업로드하기
실습 자료 : https://github.com/siyoungoh/nodejs-ecr
GitHub - siyoungoh/nodejs-ecr
Contribute to siyoungoh/nodejs-ecr development by creating an account on GitHub.
github.com
- 순서
- 본인 레파지토리에 실습 자료 fork 하기
- AWS - ECR 레파지토리 만들기
- AWS - github action을 통해 접근할 수 있는 접근권한 IAM 설정하기
- github secrets에 AWS 설정값 등록하기
1. 본인 레파지토리에 실습 자료 fork

실습 자료 Github 주소에 들어가서 Fork 클릭

Repository name 설정 후 Create fork 클릭
2. AWS - ECR 레파지토리 만들기
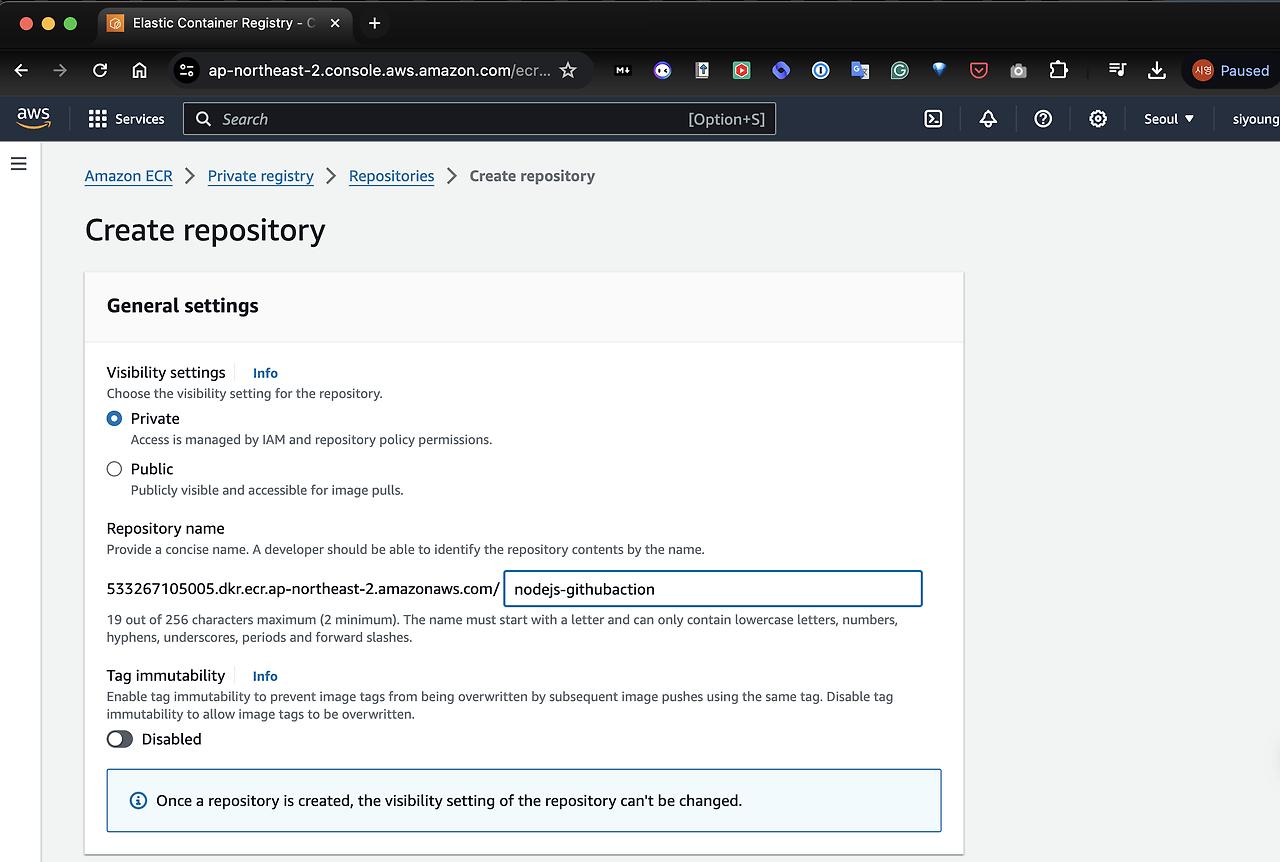
AWS 사이트에 접속해 Create repository 클릭
3. AWS - github action 을 통해 접근할 수 있는 접근 권한 IAM 설정하기

User 생성 후, Access key, screte 만들기

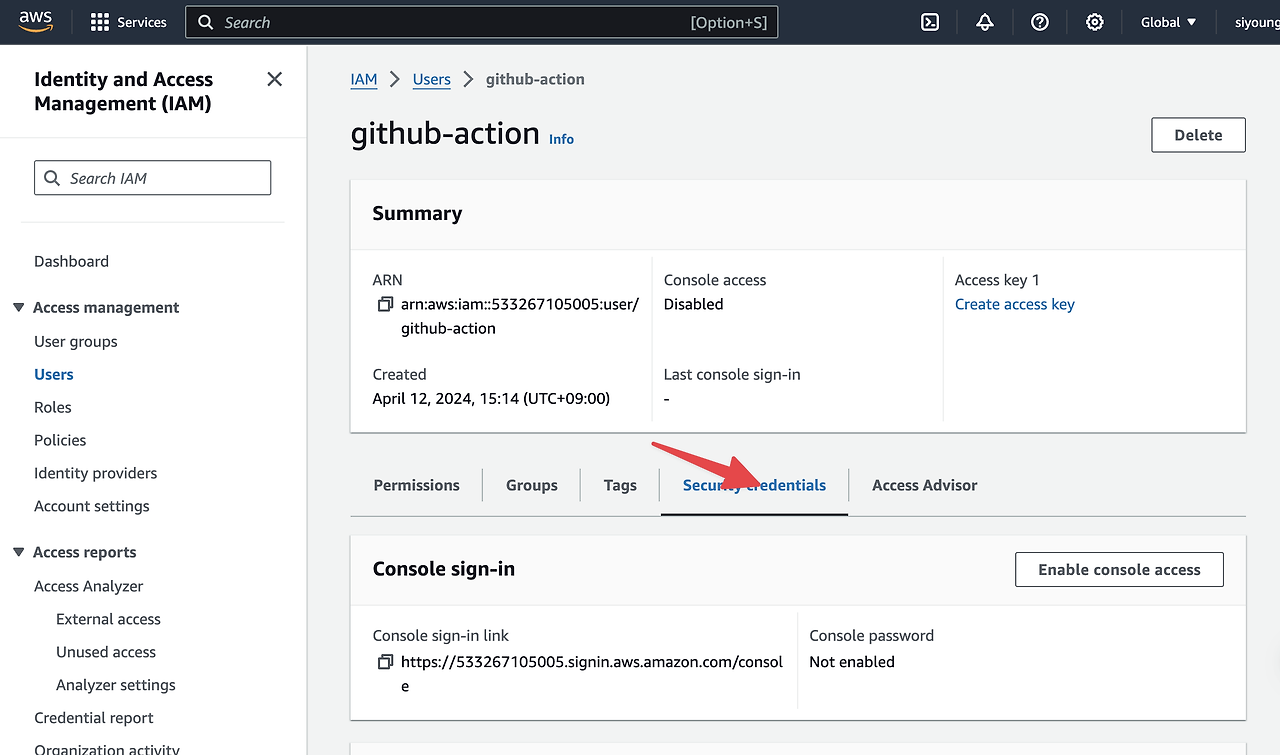



- csv로 저장한 후에 나중에 불러와서 github secrets에 등록할 예정 (ACCESS_KEY_ID, SECRET_ACCESS_KEY)
4. User 권한에 ECR 관련 권한 추가하기

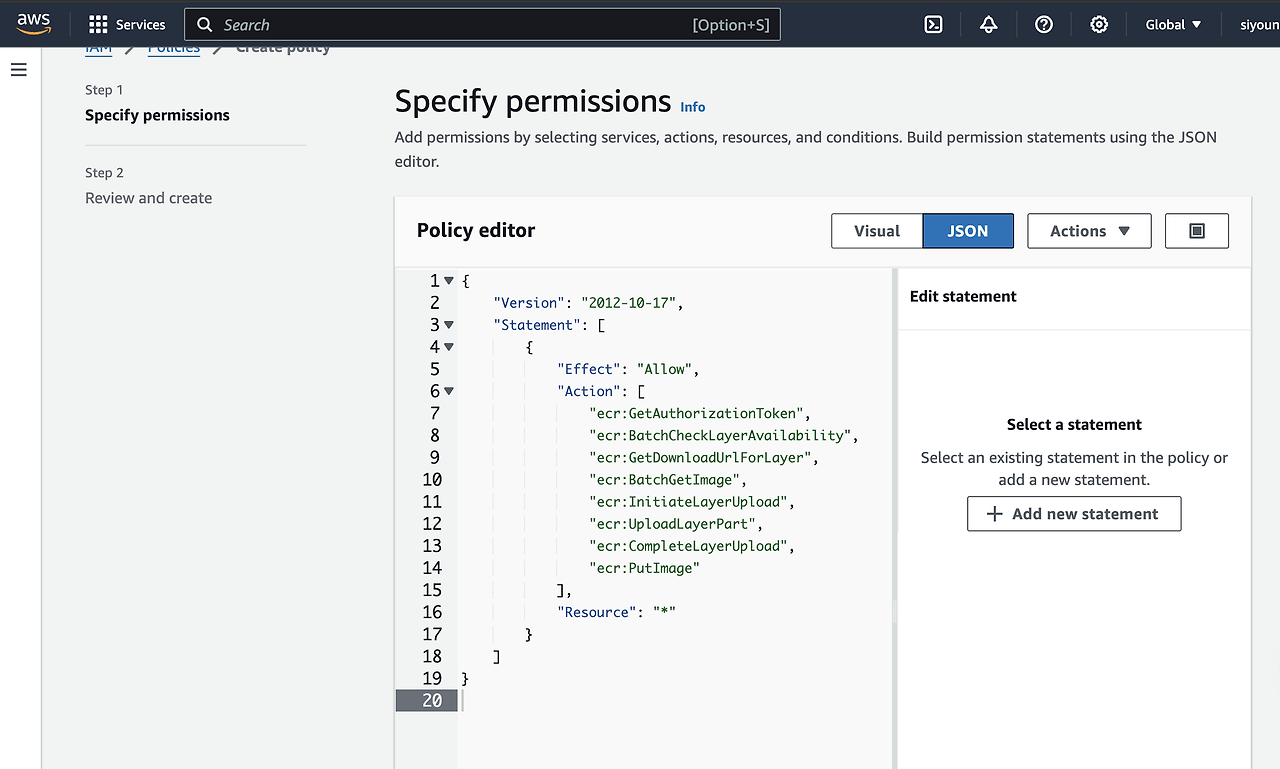
아래 코드를 복사하여 붙여넣기
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage",
"ecr:InitiateLayerUpload",
"ecr:UploadLayerPart",
"ecr:CompleteLayerUpload",
"ecr:PutImage"
],
"Resource": "*"
}
]
}


5. github secrets에 AWS 설정값 등록하기
저장해둔 ACCESS_KEY_ID, SECRET_ACCESS_KEY 를 입력
REPO_NAME는 처음에 만들어둔 nodejs-githubaction 레파지토리명 입력

main 브랜치에 commit (github action의 trigger)하여 ECR에 제대로 배포되는지 확인되면 성공.
주요 배포 전략
로컬 환경 배포 VS 프로덕션 환경 배포
- 로컬 환경에서의 배포와 프로덕션 환경에서의 배포는 여러 중요한 차이점이 있다. 각 환경의 목적과 요구 사항에 따라 배포 방식, 설정, 관리 접근법이 달라진다.
- 목적과 사용 범위
- 로컬 환경 배포: 주로 개발자가 개인적으로 사용하는 환경으로, 개발 중인 애플리케이션의 코드 변경을 테스트하고 디버깅하는 데 사용됨. 이 환경은 실험적이고 빠른 변경이 가능하며, 실시간 사용자 트래픽이나 외부에서의 접근은 없음.
- 프로덕션 환경 배포: 실제 사용자가 사용하는 환경으로, 안정성, 보안, 성능이 매우 중요함. 이 환경은 고가용성과 높은 성능을 유지하기 위해 세심하게 관리되고, 변경 사항은 철저히 테스트 후에 적용됨.
- 설정과 구성
- 로컬 환경: 일반적으로 개발 편의성을 위해 간소화된 설정을 사용함. 예를 들어, 보안 설정이나 데이터베이스 연결이 실제 운영 환경보다 덜 복잡할 수 있음.
- 프로덕션 환경: 보안, 데이터 무결성, 백업 등을 포함한 모든 운영 관련 최적화가 필수적임. 또한, 트래픽 부하를 관리하기 위해 로드 밸런서, 클러스터링, 캐싱 전략 등이 구현됨.
- 테스트와 검증
- 로컬 환경: 개발자는 주로 기능적인 검증이나 단위 테스트를 수행함. 종종 통합 테스트도 로컬에서 수행되지만, 모든 종류의 테스트를 포괄하기에는 한계가 있음.
- 프로덕션 환경: 배포 전에 여러 단계의 테스팅 환경(개발, 테스트, 스테이징)을 거침. 이 과정에서 성능 테스트, 보안 테스트, 부하 테스트 등이 포함되어, 프로덕션에 배포되기 전에 애플리케이션이 모든 기준을 충족하는지 확실하게 검증됨.
- 배포 자동화와 롤백
- 로컬 환경: 배포는 대부분 수동으로 진행될 수 있으며, 간단한 스크립트를 사용할 수도 있음.
- 프로덕션 환경: 배포 프로세스는 자동화되어 있으며, 종종 지속적 통합/지속적 배포(CI/CD) 파이프라인을 통해 관리됨. 자동 롤백, 블루/그린 배포, 카나리 배포 등의 전략을 사용하여 신중하게 변경을 적용함.
- 모니터링과 로깅
- 로컬 환경: 기본적인 로깅 도구를 사용하거나 때로는 디버깅 출력만으로도 충분할 수 있음.
- 프로덕션 환경: 고급 모니터링 및 로깅 시스템을 구축하여 실시간으로 시스템 성능을 모니터링하고, 장애를 신속하게 탐지하며 대응할 수 있음.
- 이러한 차이점을 고려하여, 로컬과 프로덕션 환경에서의 배포 전략을 적절히 계획하고 실행하는 것이 중요함. 이는 애플리케이션의 개발 단계에서부터 실제 사용자에게 서비스를 제공하는 단계까지 효율적이고 안정적으로 이행될 수 있게 해줌.
배포 전략
- 배포 전략은 소프트웨어 업데이트를 사용자에게 제공하는 방법을 정의함. 각 전략은 특정 목표와 환경에 적합하며, 신뢰성 있는 배포와 빠른 롤백, 사용자 중단 최소화를 위해 사용됨.
- 정의: 기존 인스턴스를 점진적으로 새 버전으로 업데이트하며, 언제든 일부는 옛 버전을 유지하게 됨.
- 장점: 단순하고 리소스를 추가할 필요가 없으며, 실시간으로 롤백이 가능함.
- 예시: AWS Elastic Beanstalk은 롤링 배포를 지원하여, 애플리케이션의 새 버전을 점진적으로 배포하면서 트래픽을 조정할 수 있음.
- 정의: 블루(현재 버전)와 그린(새 버전) 두 개의 완전히 독립적인 환경을 준비하고, 트래픽을 새 버전으로 일시에 전환함.
- k8s 에서 적용 : old 버전(blue)과 새 버전(green)이 정확히 같은 인스턴스 양으로 릴리즈된 다음에 정상 동작되는지 확인하고 로드밸런서 수준에서 green 으로 트래픽을 스위칭함.
- 장점: 즉각적인 롤백이 가능하며, 새 버전의 안정성을 확보한 후 트래픽을 전환할 수 있음.
- 예시: 사용자가 주로 사용하는 금융 서비스 애플리케이션에서, 블루/그린 배포를 사용하여 시스템 다운타임 없이 버전 업그레이드를 진행할 수 있음.

- 정의: 새 버전을 소수의 사용자에게 먼저 제공하고, 문제가 없을 경우 점차적으로 확대하여 전체 사용자에게 배포함.
- 일부 사용자에게 릴리즈된 다음 전체 rollout 진행. 새 릴리즈 안정성이 의문, 테스트가 부족할 때 사용.
- 장점: 리스크를 최소화하면서 새 버전의 성능을 실제 사용 환경에서 테스트할 수 있음.
- 예시: 대형 소셜 미디어 플랫폼에서 새로운 기능을 도입할 때, 소수의 사용자 그룹에게 먼저 적용하여 반응과 성능을 평가한 후 점진적으로 확대함.
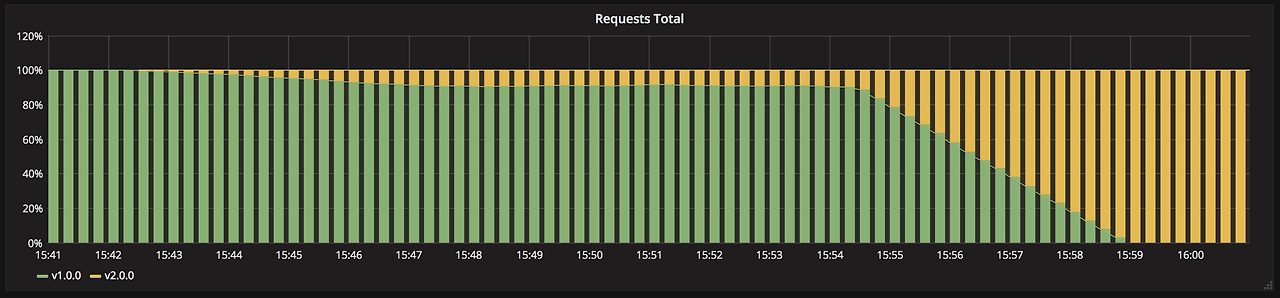
- 정의: 두 가지 이상의 버전을 동시에 배포하고, 각 버전의 성능을 비교 분석함.
- 통계 활용한 비즈니스 전략이지만, 카나리아 배포에 기능 추가해 구현할 수 있어서 소개함. 새로운 버전이 특정 조건에서 일부 사용자에게만 배포됨.

- 장점: 사용자의 반응과 선호도를 기반으로 가장 효과적인 버전을 선택할 수 있음.
- 예시: 온라인 리테일 업체가 두 가지 다른 홈페이지 디자인을 테스트하여, 구매 전환율이 더 높은 디자인을 최종적으로 선택함.
마무리
이번 온보딩 교육과정에서 도커, 쿠버네티스라는 플랫폼의 기본적인 개념들을 알게 되어 매우 만족스러웠고, 강사님께서 중간중간 들어오는 질문에도 친절히 대답해 주시고, 수업이 끝나기 전에 질문들을 정리해서 올려주시는 것도 매우 유익했다. (실습 강의 최고!)
한 가지 아쉬운 건 서버 배포 방법만 배우고 부하 테스트나 실제 도구를 사용한 실습은 직접 해보아야 한다는 점...?
그래도, 지난 2주간 CI/CD에 대해 새로운 지식을 얻는 시간이었기에 큰 보람을 느꼈다.
다음에 또 이런 온보딩 교육이 있다면 무조건 신청하는 걸로...!
'Docker' 카테고리의 다른 글
| [Docker] 도커로 로컬 서버 배포하기 (0) | 2024.04.08 |
|---|---|
| [Docker] 이미지 빌드하고 컨테이너 실행하기 (1) | 2024.04.05 |
| [Docker] Docker로 배포 경험하기 (6) | 2024.04.03 |
| [원티드] 포트폴리오에 Docker로 배포 경험 더하기 | 프리온보딩 BE 챌린지 4월 (0) | 2024.03.21 |



